
You need to make AI guidelines for your lab
Here's why you should, and how to start

Generative AI is now part of academic research. A recent Nature feature found that PhD students are using AI tools daily to search the literature, write code, draft manuscripts, analyze data, and interpret results (Nordling 2026). Some use it constantly and swear by it; others avoid it, worried about the cost to their development. Most fall somewhere in between, making up their own rules as they go, with little guidance from their supervisors.
Can you blame them? They’re under pressure to be productive, like everyone else. They see peers at other labs using AI freely. And frankly, these tools are genuinely powerful; I use them regularly in my own work. I am not anti-AI; quite the opposite. I think AI can accelerate literature searches, catch errors in your code, help you learn new syntax, improve your writing, and let you iterate faster on analyses you already understand. I’m enthusiastic about what these tools make possible.
However, there is a real problem with unrestricted AI use during the training period, and it’s one that most PIs haven’t grappled with yet. A Nature editorial last year made the case that doctoral training needs a fundamental rethink in an AI world (Sen Gupta 2025). Among other things, the editorial notes that only 5% of European universities surveyed felt their existing AI guidelines for doctoral education were sufficient. I agree that a rethink is needed. And since universities are not providing clear guidelines, I think it can start at the lab level.
The purpose of a PhD is to develop independent scientific expertise: learning to think critically, analyze data, write clearly, and form your own judgment. When AI automates those cognitive tasks, trainees can produce polished outputs while bypassing the learning process that those tasks are designed to provide. This doesn't mean trainees are doing something wrong. But they can't be expected to set these norms themselves - they don't yet have the experience to know where the line should be. Setting norms around AI use is a mentorship responsibility. I recently went through the exercise of writing AI guidelines for my lab, and I think every PI should do the same. Here’s why, and how.
The core issue
The best framing I’ve found comes from Arjun Krishnan, who articulates a principle he calls “expertise before augmentation” in a recent pair of papers (one that lays out the conceptual framework (Krishnan 2026a), and another that provides practical guidelines (Krishnan 2026b)). The argument is simple. Previous tools (like calculators, statistical software, or search engines) automated mechanical execution. You chose the statistical test; R executed it. You decided what to search; Google found it. Generative AI is different. It automates the cognitive work itself: reasoning, synthesis, judgment. Krishnan illustrates this with a simple framework, shown in Figure 1 from the paper below.
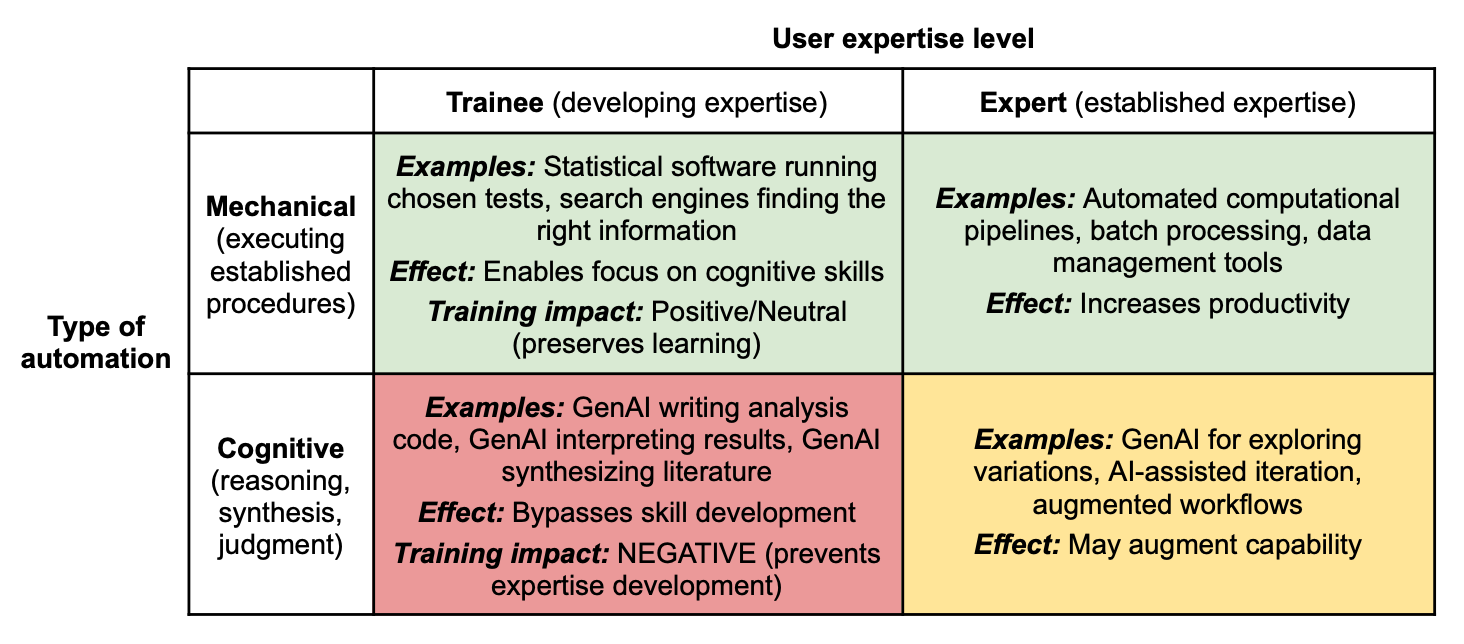
The impact of automation depends on both what is automated (rows) and who is using it (columns). Automating mechanical processes (like running a statistical test or formatting citations) preserves learning regardless of expertise level. But automating cognitive processes (like choosing the analytical approach, interpreting results, or synthesizing arguments) has opposite effects depending on the user: it augments experts who can verify the output, and undermines trainees who can’t.
For an experienced researcher, AI is great. You know enough to guide the tool, catch its errors, and work independently when it fails. But for a trainee still developing those capabilities, the same tool can bypass the learning process entirely, while producing outputs that look polished enough to mask the gap.
AI also changes the nature of the task itself. Instead of doing the work, you're now reviewing it. That sounds easier, but it's not: verifying that an analysis or a text is correct often requires deeper understanding than producing it in the first place. Krishnan calls this the “verification paradox”: you can’t verify AI outputs in areas where you haven’t yet developed competence, because verification requires the expertise you’re still building. Consider a concrete example. A trainee asks AI to write a differential abundance analysis for a microbiome dataset. The code runs without errors, the figures look professional, the statistical tests seem reasonable, and the interpretation sounds confident. But is the normalization appropriate for compositional data? Are the statistical assumptions met? Are there batch effects that the analysis ignores? These are the kinds of questions that require domain expertise to even think to ask, and that expertise is what the trainee is supposed to be developing. The result is a circular trap: the AI produces work that looks right, but the trainee can’t tell whether it actually is.
There’s a deeper issue here, too. The struggle of figuring out the right analysis approach, wrestling with an unexpected result, or trying to turn a messy set of findings into a coherent story is not an obstacle to learning. It is the learning. That’s how you develop judgment, build intuition, and find your own voice as a scientist.
Writing AI use guidelines for your lab
Here’s a process that worked for my lab. Every group has its own culture, emphasis, and style, so adapt as needed, but the basic framework is transferable.
Start with a journal club. Before writing anything down, have a lab discussion. The journal club format worked well for this, with the two Krishnan papers (Krishnan 2026a; Krishnan 2026b) as the assigned reading. You can structure it however works for your group: a set of prepared questions, a free-flowing conversation, or something in between. The format matters less than creating a space for open conversation about how AI fits into scientific training.
Discuss the substance. Go through the paper’s tables and examples. Discuss specific scenarios from the papers and how they map onto your lab’s work. Talk about where the line falls between productive use and dependency. Consider the types of AI errors Krishnan catalogs (hallucinated citations, inappropriate statistical tests, confirmation bias) and discuss which ones are most relevant to your field. You can also discuss when the temptation to reach for AI is strongest: when a task is boring, or when it’s hard and uncomfortable? Kaplan, Palitsky & Raison (2025) call this latter pattern “machinal bypass”; using AI not to support thinking but to sidestep it, especially when we feel stressed or doubtful of our capabilities.
Don’t underestimate the conversation itself: even without producing a written document, our lab discussion was extremely valuable. It surfaced assumptions, clarified where people saw genuine gray areas, and made clear that the a guideline would be a useful resource. If you do nothing else, have the conversation.
Draft guidelines. After the discussion, draft a short document. This doesn’t have to be a rigid policy, but more a set of principles with concrete examples relevant for your lab’s work. Every lab’s document will look different, but for computational labs, I’d suggest covering at least these three areas:
Accountability. If you use AI, you own the output. This is the non-negotiable foundation. AI-generated work that contains errors (wrong statistical tests, hallucinated citations, bugs in code, etc) is your responsibility. This means every AI output needs to be verified. Verification means you understand what every step does, why it’s appropriate for your data and experimental design, and what the result should approximately look like. If you can’t perform that level of verification for a given task, that’s a signal that AI use for that task is premature.
Writing. This is where I think the stakes are highest. As Hazelett (2025) argues, and I completely agree, writing is the single most important skill in science (Hazelett 2025). The struggle to organize your argument, decide what matters, and articulate what your results mean is the intellectual work itself. When AI writes your first draft, the task gets done, but the thinking doesn’t happen. In our guidelines, first drafts of Results, Discussion, and Introduction sections should be the trainee’s own work. AI can help with grammar, with tightening prose after revision, or with critiquing the logic of an argument you’ve already made. But the hard part of forming the argument needs to be yours.
Analysis. For analysis, the question isn’t “Can AI do this?” but “Can I verify what AI produces?” For example, if you understand mixed-effects models and want to learn the syntax of a new R package, AI is a great tool. If you’re asking AI to design a statistical model for a differential abundance analysis, you’re outsourcing the scientific judgment that your training is supposed to build. The same applies to interpreting results: asking AI what your differentially abundant taxa mean in a certain context requires domain knowledge, understanding of your experimental design, and awareness of the data’s limitations.
I’d recommend keeping the tone advisory rather than punitive. The threshold throughout should be functional: can you do the task, explain your reasoning, and catch your own errors? If yes, AI could be a good option. If not, that’s useful information about where you are in your development, not a judgment.
These guidelines won’t be perfect. Ours certainly aren’t, and they’ll evolve as the tools change and as we learn more about how AI affects training. But a flawed document that starts a conversation is better than no document and no conversation. The norms on AI use are being set right now, whether you write them down for your lab or not. You might as well be the one setting them.
References
Hazelett DJ (2025). An open letter to graduate students and other procrastinators: it’s time to write. Nature Biotechnology 43:447–450. https://www.nature.com/articles/s41587-025-02584-1
Kaplan DM, Palitsky R, Raison CL (2025). The ‘machinal bypass’ and how we’re using AI to avoid ourselves. PNAS 122(51):e2518999122. https://doi.org/10.1073/pnas.2518999122
Krishnan A (2026). Build expertise first: why PhD training must sequence AI use after foundational skill development. https://doi.org/10.5281/zenodo.18649847
Krishnan A (2026). Expertise before augmentation: a practical guide to using generative AI during research training. https://doi.org/10.5281/zenodo.18452319
Nordling L (2026). AI and the PhD student: friend or foe? Nature 651:24–27. https://www.nature.com/articles/d41586-026-00843-y
Sen Gupta A (2025). PhD training needs a reboot in an AI world. Nature 647:27–28. https://www.nature.com/articles/d41586-025-03572-w
Who will follow the rules Ran? Scientists themselves have already fallen into the trap! Check a recent example: https://www.linkedin.com/posts/panagiotis-gioannis-3b8605186_local-bernstein-theory-and-lower-bounds-share-7446460788380172288-eTB-
Mainly has to do with the researcher's own indecision. It's not that we haven't been taught them, we just don't want to apply them. Like for example (please see also the internal links):
https://www.linkedin.com/posts/panagiotis-gioannis-3b8605186_how-a-phd-is-like-riding-a-bike-activity-7412404011238113281-okjC
[How a Ph.D. is like riding a bike]
However, concerns have already begun:
https://www.linkedin.com/posts/panagiotis-gioannis-3b8605186_for-open-research-to-work-research-institutions-share-7444688122069573632-iT6Y
[For open research to work, research institutions and publishers need to collaborate]
Very instructive article! As a Master's student trainee (also studying AI in health), I couldn't agree more with your observation: developing high-value skills by ourselves should be our number one priority, without being anti-AI, as you said...